¶ Создание моделей
Для работы с системой в неё должны быть загружены данные. Для этого в разделе Модели данных создайте новую модель.

При первом входе будет отображена пустая страница, на которой можно создать модель. Нажмите Создать модель данных для создания новой модели.

В появившемся окне выберите способ создания модели:
- вручную,
- импортировать из файла.

При создании модели вручную введите название модели данных и нажмите Создать модель данных. Далее, перейдите в созданную модель и воспользуйтесь Быстрым стартом или заполните данные самостоятельно.
При создании модели путём импорта данных, выберите пункт Импортировать из файла VKPM (JSON) и добавьте файл с данными в область размещения файла. Нажмите Создать модель данных.
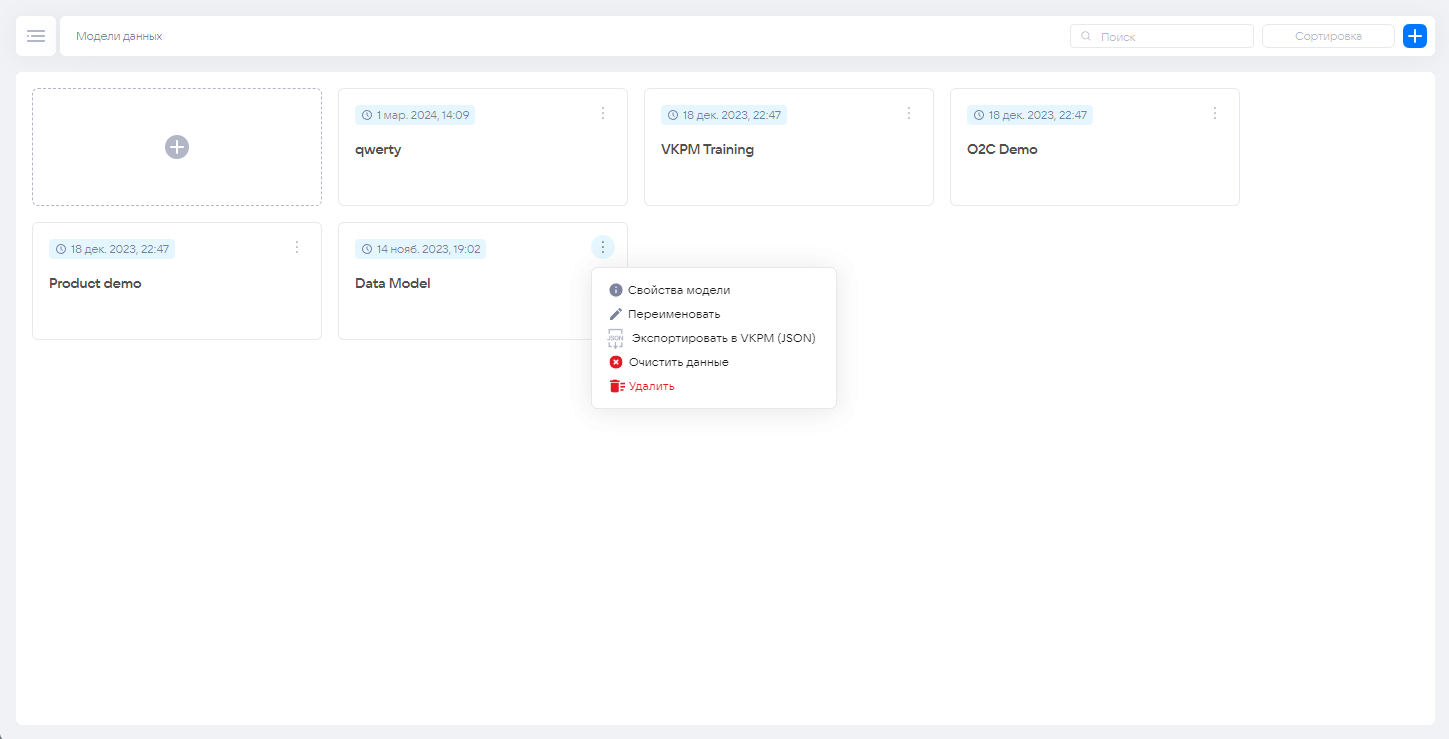
Если модели данных в системе уже есть, то отобразится список загруженных моделей. С каждой из них можно выполнить действия:
- открыть свойства модели,
- переименовать,
- экспортировать в VKPM (JSON),
- очистить данные,
- удалить (при удалении модели все данные очищаются автоматически).
¶ Работа с моделями данных
Если зайти в модель данных то отобразится интерфейс с выбором способа загрузки данных:
- В упрощенном режиме через Быстрый старт → Файловая загрузка.
- В ручном режиме через Самостоятельную работу с данными → Интеграции с внешними источниками.
¶ Очистка моделей
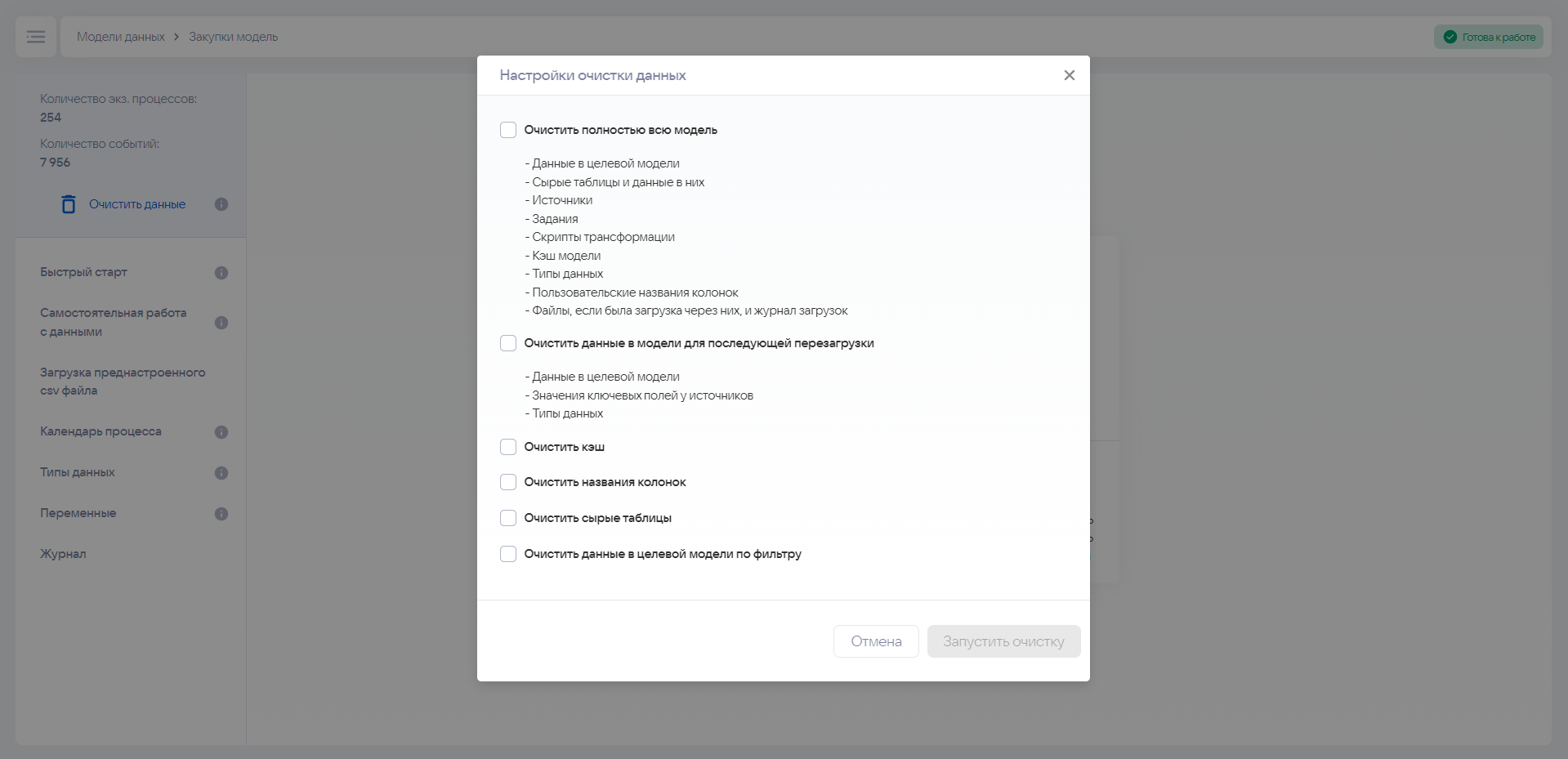
Для очистки модели нажмите кнопку Очистить данные в левом верхнем углу.
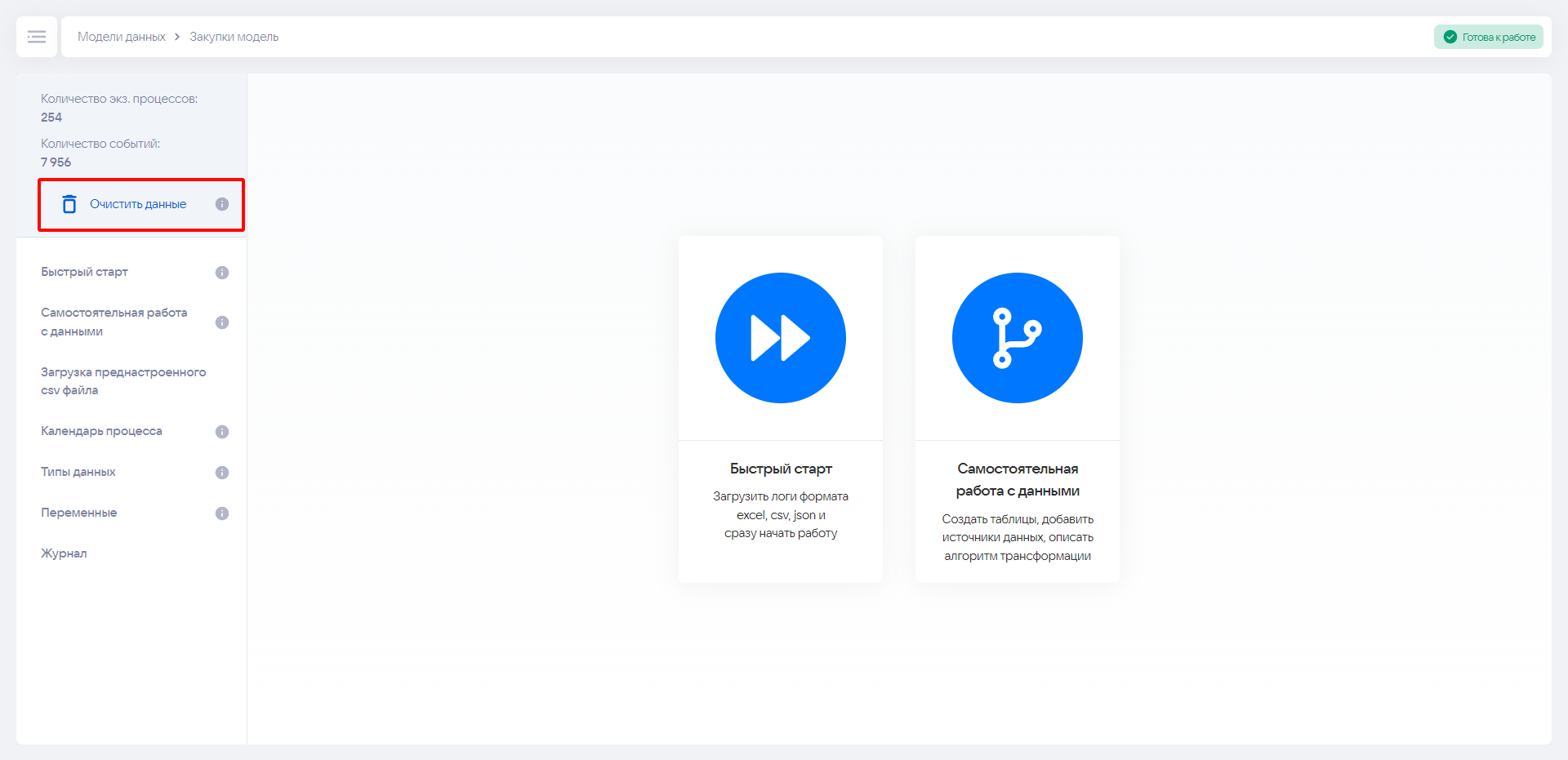
Нажатие на кнопку вызовет меню с настройками очистки. В нем можно выбрать одно или несколько правил для очистки данных внутри модели.
¶ Быстрый старт
Быстрый старт позволяет загрузить данные с помощью файлов в формате Excel, CSV, JSON и XML. Интерфейс «Быстрого старта» представлен в виде действий по шагам.
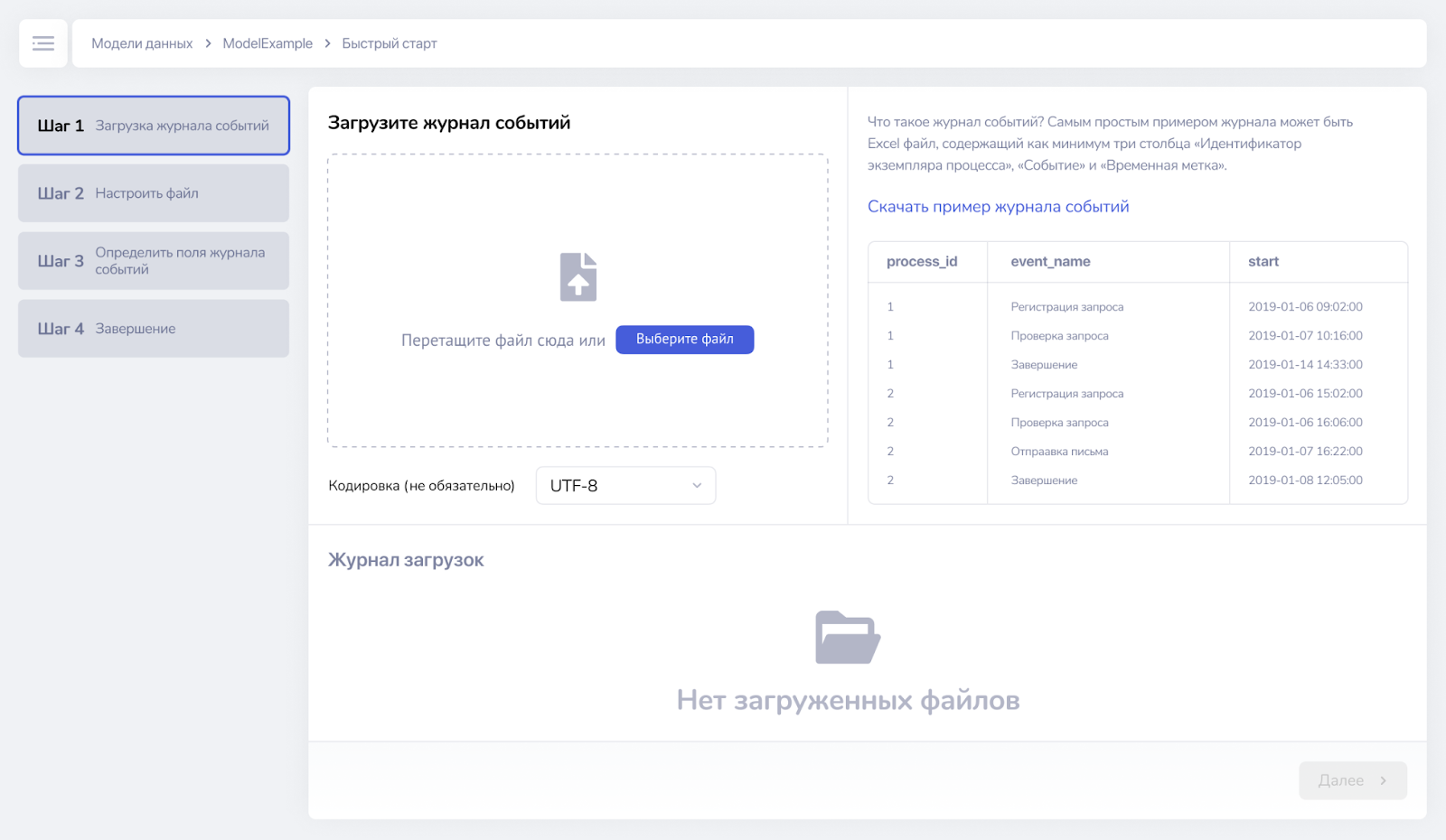
¶ Шаг 1. Загрузка журнала событий
На этом шаге происходит загрузка данных в систему. Система попытается автоматически определить кодировку файла. Если это не удается сделать, то кодировку можно выбрать руками.
Также на этом экране можно скачать пример журнала событий.
Интерфейс позволяет догружать данные в систему. Например, если файл большой и его разделили на несколько частей, или когда происходит загрузка данных за новый временной период.
В том случае, если в загруженных данных есть идентификатор события, то при его наличии в догружаемом файле, произойдет обновление старой строки события без дублирования данных. Если в загруженных данных или в догружаемом файле идентификатора события нет, то события будут дублированы.
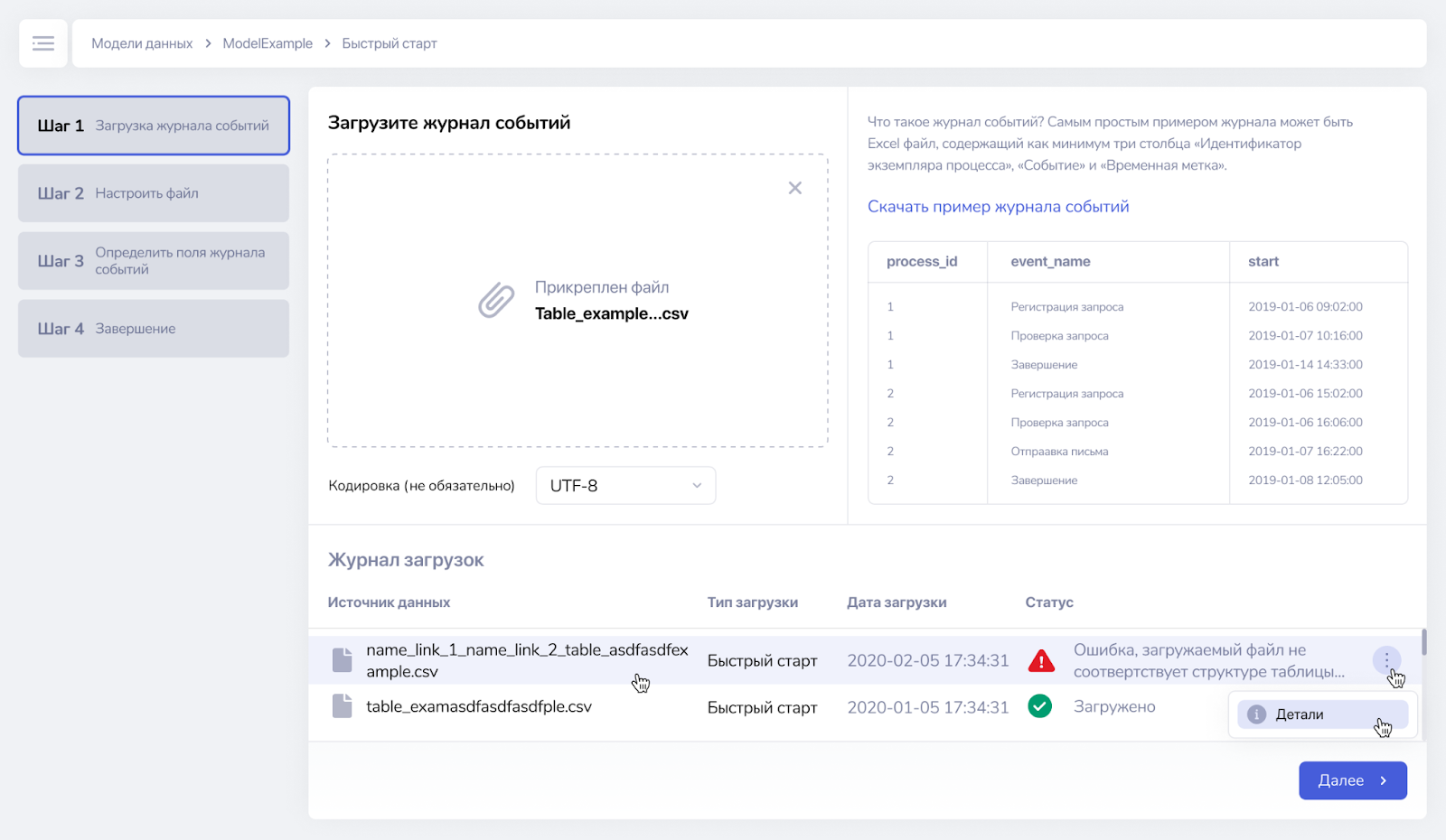
При загрузке данных автоматически заполняется журнал загрузок, содержащий следующую информацию:
- источник данных (имя файла),
- тип загрузки,
- дата загрузки,
- статус (загружено/ошибка).
Каждую ошибку загрузки можно просмотреть через меню Детали.
¶ Шаг 2. Настроить файл
На шаге 2 отображается таблица с загруженными данными.
Система автоматически распознает типы данных в каждой колонке и отобразит их пользователю: можно согласиться и перейти на следующий шаг или поменять их. Важно проверить каждую колонку на правильность типа данных, чтобы, например, в дальнейшем работать в системе с числами как с числом, а не как с текстом.
Формат даты также будет распознан автоматически. Его можно поменять, если он неверный.
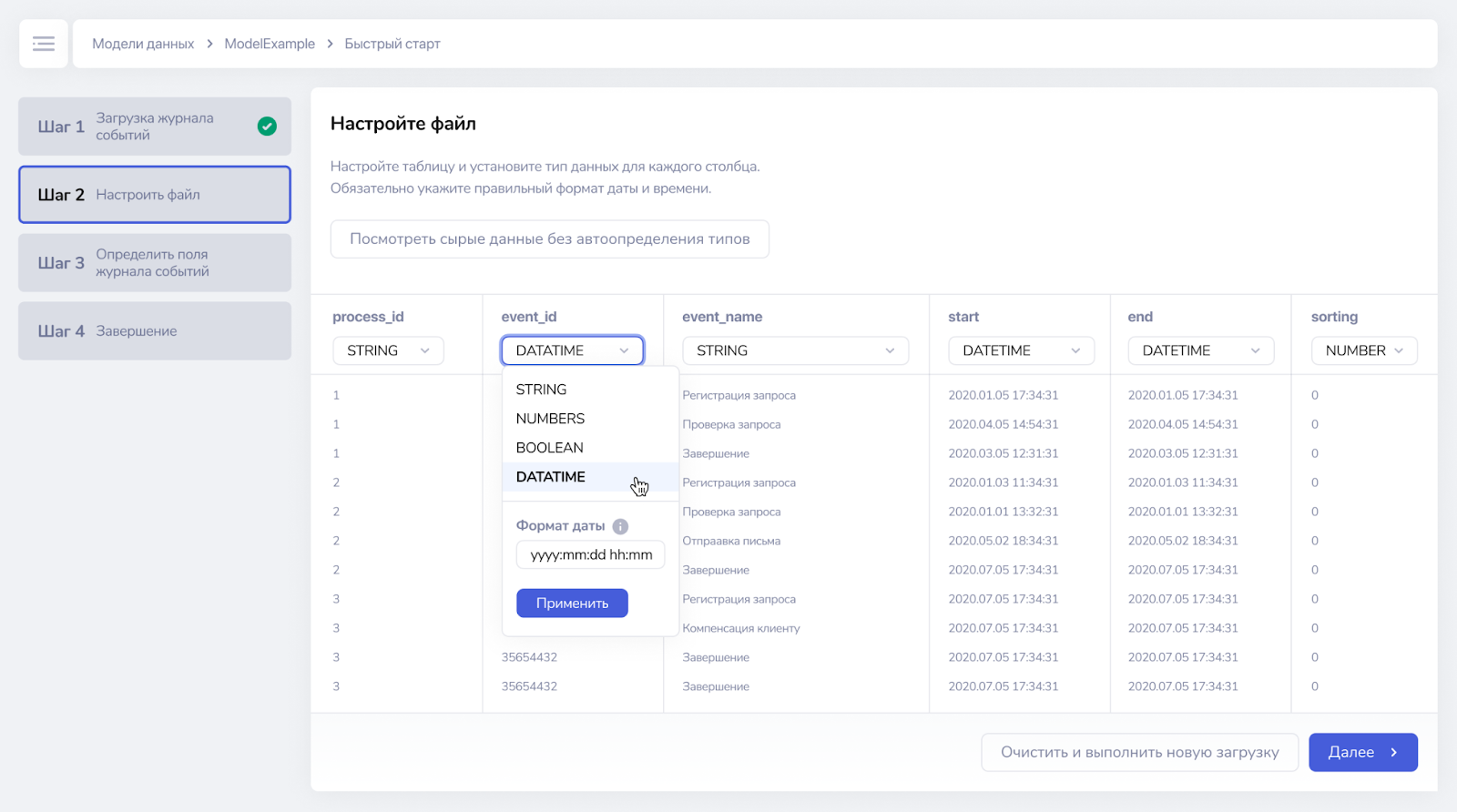
Если система совсем неверно распознала типы данных или форматы дат, то нажатием на кнопку Посмотреть сырые данные без автоопределения типов можно увидеть, что подавалось на вход системе, не открывая на компьютере загружаемый файл.
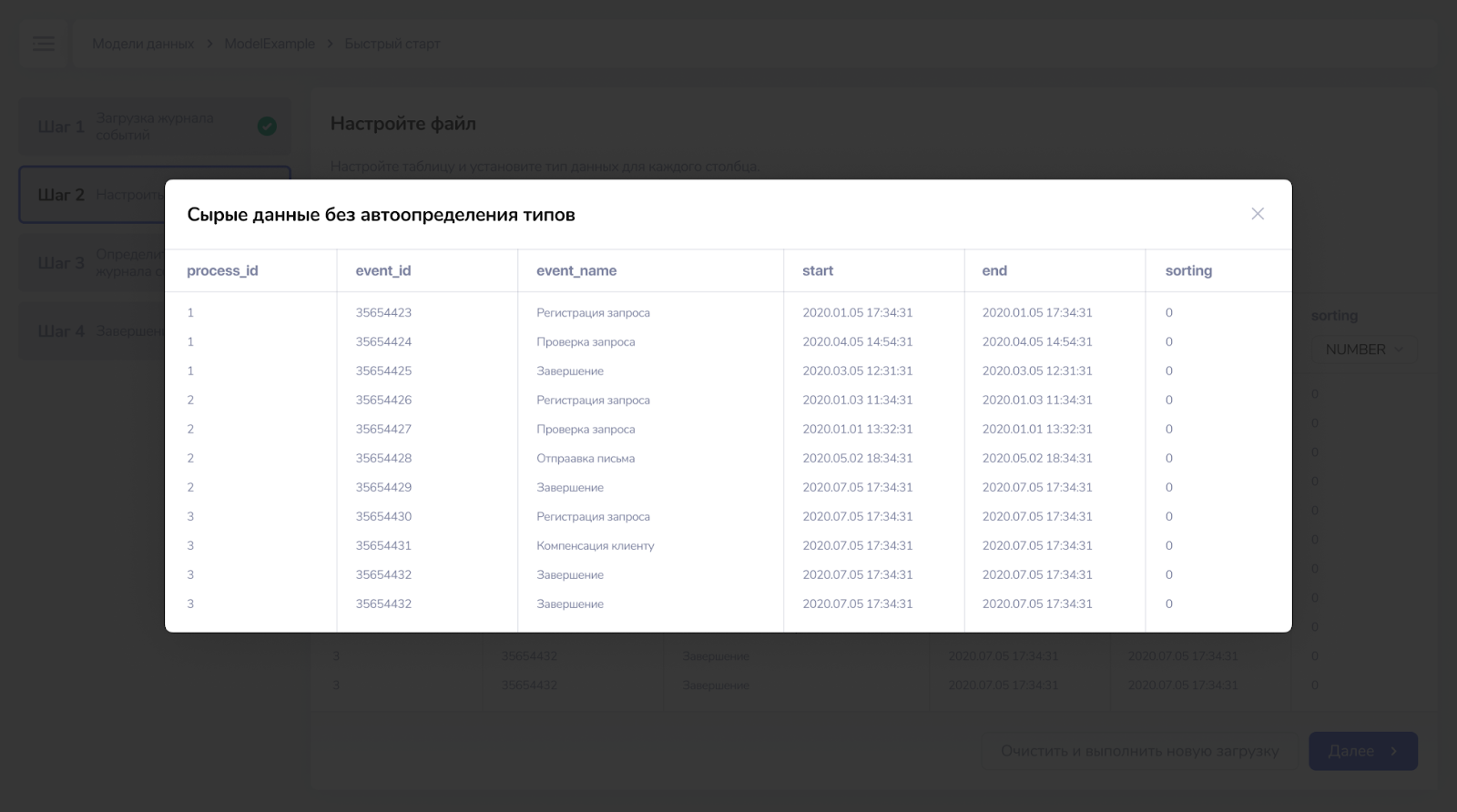
¶ Шаг 3. Определить поля журнала событий
В интерфейсе шага 3 необходимо указать, какие поля из загружаемого файла соответствуют обязательным и необязательным полям журнала событий для process mining.
Обязательные поля:
- Идентификатор экземпляра процесса,
- Имя события.

При помощи зажатой ЛКМ перетщите поля из верхней части на колонки в таблице под ними. Когда все обязательные поля будут перенесены, можно будет перейти на следующий шаг.
Система обработает только те поля, которые вынесены на таблицу, а остальные пропустит и в системе их нельзя будет увидеть.
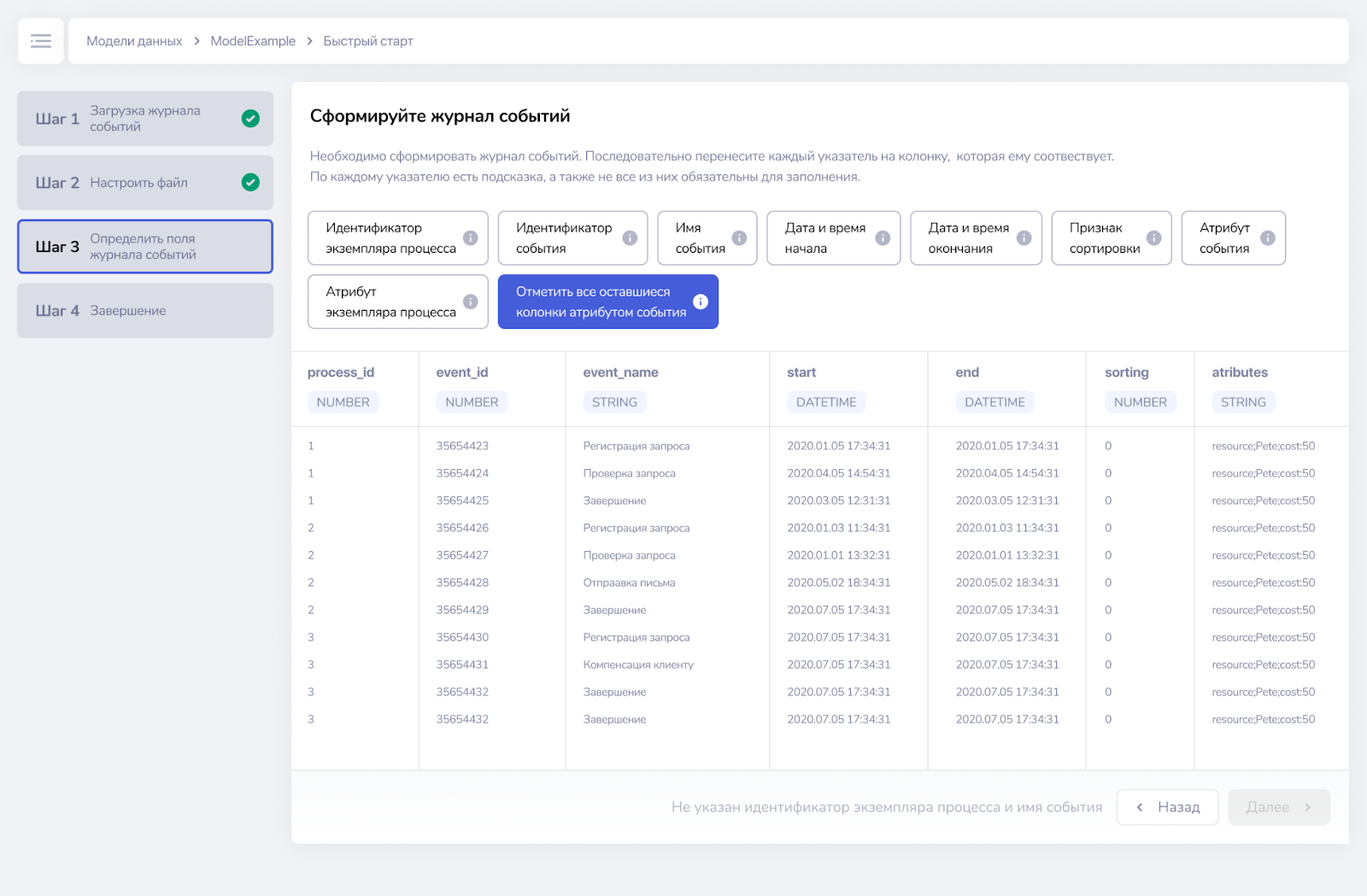
¶ Шаг 4. Завершение
Последний шаг отображает прогресс загрузки данных. Время обработки зависит от объема данных.
На этом шаге можно отменить загрузку, она произойдет не моментально. Пользователю будет отображено сообщение «Получен запрос на отмену. Пожалуйста, подождите». Если отменить загрузку, то данные будут загружены не в полном объеме и их рекомендуется очистить перед следующей загрузкой. На это будет указывать статус модели.
На этапе «Расчет статистики» отмену выполнить нельзя. Данный этап рассчитывает базовые показатели: цепочки, длительности, количество шагов по экземплярам.

¶ Загрузка преднастроенного CSV файла
¶ Формат файлов
Журнал событий грузится в систему путем подгрузки одновременно двух CSV-файлов:
- process.csv - содержит экземпляры процессов и их атрибуты;
- event.csv - содержит события к экземплярам с временной меткой и названием шага.
Примеры файлов: https://cloud.mail.ru/public/YWiv/potPiUN8L
Описание файла event.csv:
- process_id — идентификатор экземпляра процесса (все события с этим идентификатором принадлежат одному экземпляру).
- event_id — уникальный идентификатор события (идентификатор строки).
- event_name — наименование события.
- start — дата и время начала события. Колонка необязательная, если есть колонка end. При отсутствии start, значение будет равно значению из поля end.
- end — дата и время окончания события. Колонка необязательная, при его отсутствии значение будет равно значению из поля start.
- sorting — признак сортировки для определения последовательности событий в цепочке, когда дата и время совпадают. Заполнить нулями если нет параллельных событий. Является обязательным полем.
- attributes — дополнительные атрибуты к каждому событию, лежат в одной колонке. Может быть пустой.
Описание файла process.csv:
- process_id — идентификатор экземпляра процесса.
- attributes — дополнительные атрибуты к каждому экземпляру процесса, лежат в одной колонке. Может быть пустой.
Общие правила заполнения CSV-файлов:
- Используется единый шаблон загрузки для всех данных.
- CSV-шаблоны имеют 7 неизменяемых колонок файла event.csv и 2 неизменяемых колонки файла process.csv разделенных запятой, данные в колонках указываются в двойных кавычках
". - Экранирование кавычек во всех колонках производится двойными кавычками
"". - Кодировка UTF-8.
- Десятичный разделитель для числовых значений указывается точкой, если над числами будут проводиться математические операции. Например "cost:50.4".
- Все дополнительное экранирование символов внутри attributes:
- запятая
,— обратный слэш плюс запятая\,. - двоеточие
:— обратный слэш плюс двоеточие\:. - обратный слэш
\— два обратных слэша\\.
- запятая
- Поля типа дата/время:
- Кодируются по шаблону: YYYY-MM-DD HH:mm:ss.
- Если в дате нет времени, то значение времени задается как в исходном файле 00:00:00.
- Предполагается что все загружаемые даты в зоне GMT.
Пример заполнения attributes:
- Оригинал:
атрибут “поставщик” со значением ООО “Экспресс: Канцелярские товары, расходные материалы\картриджи” - С правилами экранирования:
“поставщик:ООО "”Экспресс: Канцелярские товары, расходные материалы\\картриджи”””
Файлы CSV можно также загрузить с разделителем колонок точка с запятой, сами колонки при этом будут не в кавычках. Все атрибуты процесса и событий в колонке attributes при этом разделены запятой, правила экранирования такие же. Обычно такой формат получается при автоматической конвертации из Excel-документа в CSV.
¶ Интерфейс загрузки
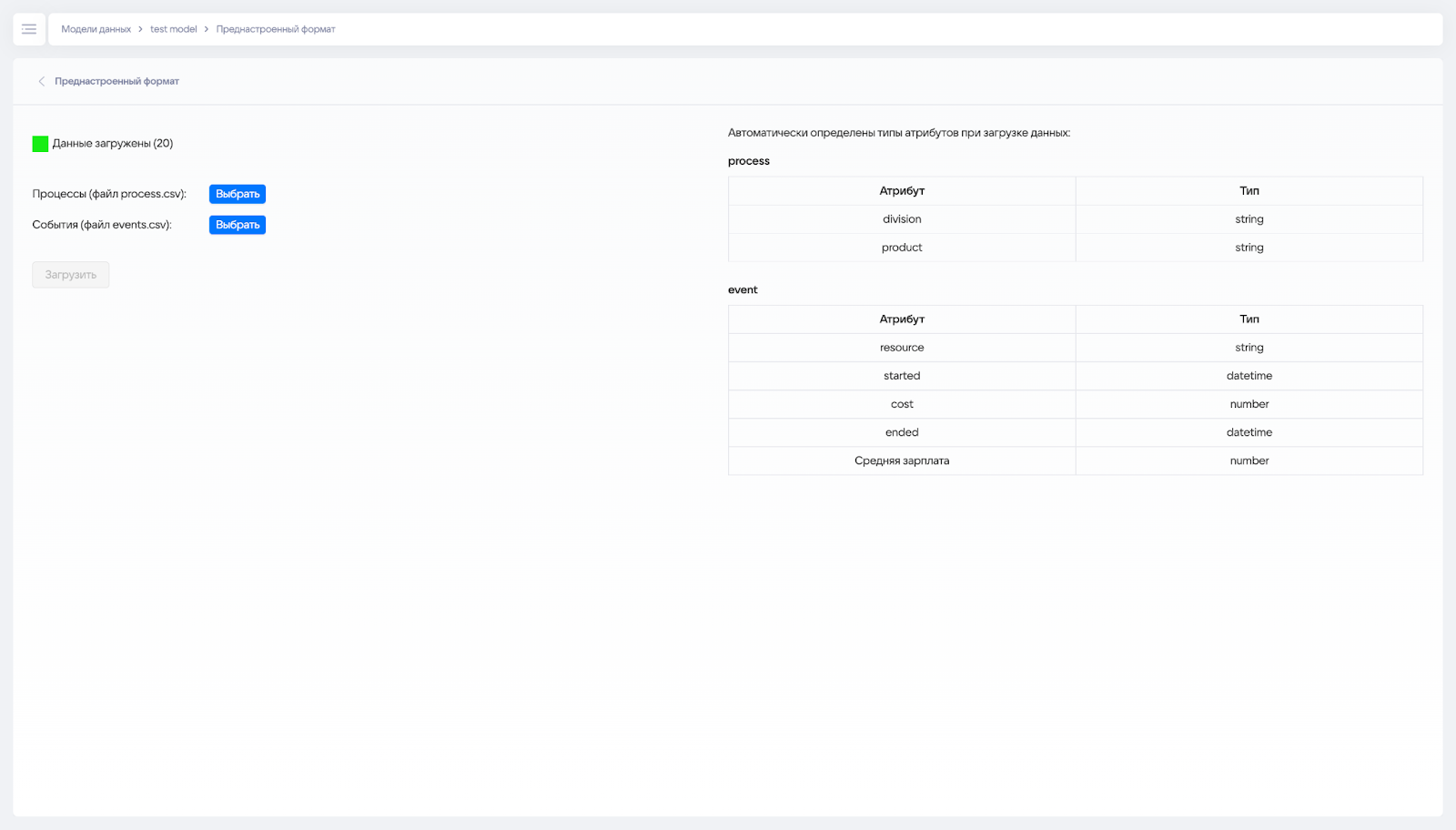
Страница для подгрузки журнала событий в преднастроенном формате доступна из основного меню в разделе «Преднастроенный формат».
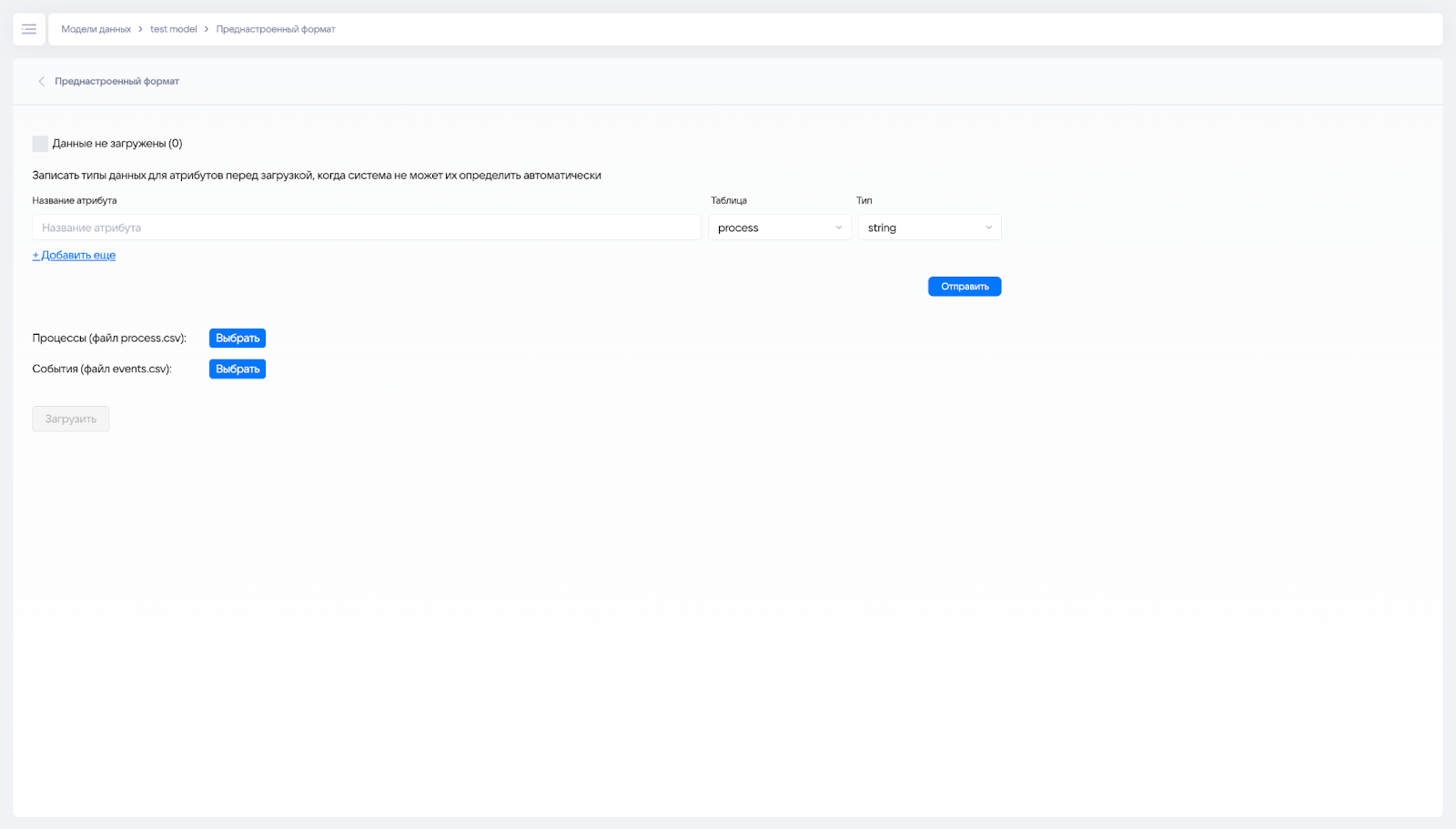
Система автоматически определяет типы загружаемых данных. Если система определяет типы данных неверно, то их можно задать заранее через интерфейс. После загрузки на странице с моделью показываются атрибуты и их типы.
¶ Самостоятельная работа с данными — получение данных из внешних источников
Для получения информации из внешних источников необходимо перейти в раздел «Модели данных», выбрать нужную модель и зайти в раздел «Самостоятельная работа с данными».
Для загрузки данных подходит любая совместимая ODBC база данных. По умолчанию подключены PostgreSQL и MySQL. Для возможности работы с другими базами необходимо обратиться к разработчикам.

Интерфейс «Самостоятельная работа с данными» представлен в виде действий по шагам.
¶ Шаг 1: Таблицы
На этом шаге создаются «сырые» таблицы для временного хранения данных из внешних источников, с последующей их обработкой на Шаге 3 и загрузкой в целевую модель.
Доступные действия для таблицы:
- Создание таблицы.
- Очистка таблицы.
- Предпросмотр загруженных данных.
- Редактирование таблицы
¶ Создание таблицы
Для добавления таблицы необходимо нажать кнопку «Плюс». На выбор доступны два варианта:
- Ручное добавление — данные для заполнения таблицы вносятся вручную.
- Импорт кода — данные импортируются из базы данных путём вставки DDL-конструкции CREATE TABLE.
¶ Ручное добавление
Для создания новой таблицы вручную выберите опцию «Ручное добавление». В открывшемся окне заполните форму таблицы.
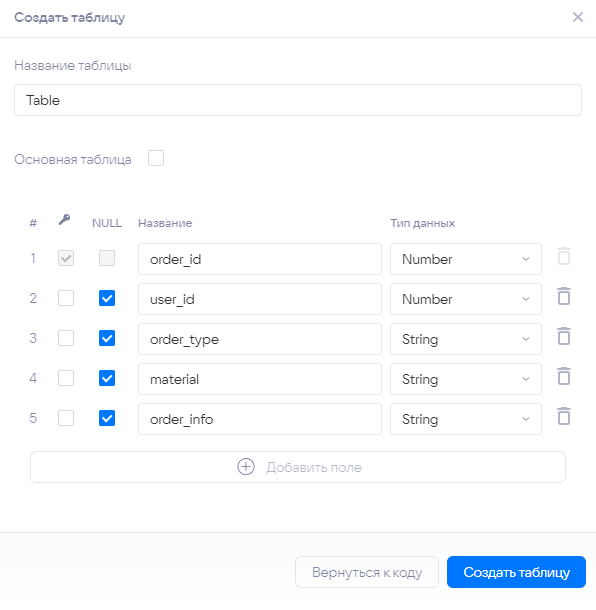
Названия создаваемых таблиц и полей таблиц должны соответствовать названиям в источнике из которого будут поступать данные. То есть допустимы названия, написанные латиницей.
¶ Импорт кода
Для создания новой таблицы напрямую из БД, выберите опцию «Импорт кода». В открывшейся форме заполните поля:
-
Название таблицы.
-
Текст CREATE TABLE из базы данных.
Пример текста:CREATE TABLE IF NOT EXISTS public.orders ( order_id integer NOT NULL, user_id integer, order_type character varying COLLATE pg_catalog."default", material character varying COLLATE pg_catalog."default", order_info character varying COLLATE pg_catalog."default", CONSTRAINT orders_pkey PRIMARY KEY (order_id) )

Нажмите продолжить.
Созданная таблица выглядит следующим образом:

¶ Редактирование таблицы
Для перехода к редактированию таблицы выполните одно из следующих действий:
- Нажмите кнопку Редактировать в верхней части блока с таблицей.
- В списке таблиц в левой части интерфейса нажмите ⁝ справа от названия таблицы и выберите пункт «Редактировать».
В открывшейся форме внесите необходимые изменения и нажмите Сохранить изменения.
¶ Шаг 2: Загрузка данных
Источники данных
На этом шаге задаются внешние источники данных, откуда будет происходить загрузка. Для этого в открывшемся окне перейдите на вкладку «Источники данных».
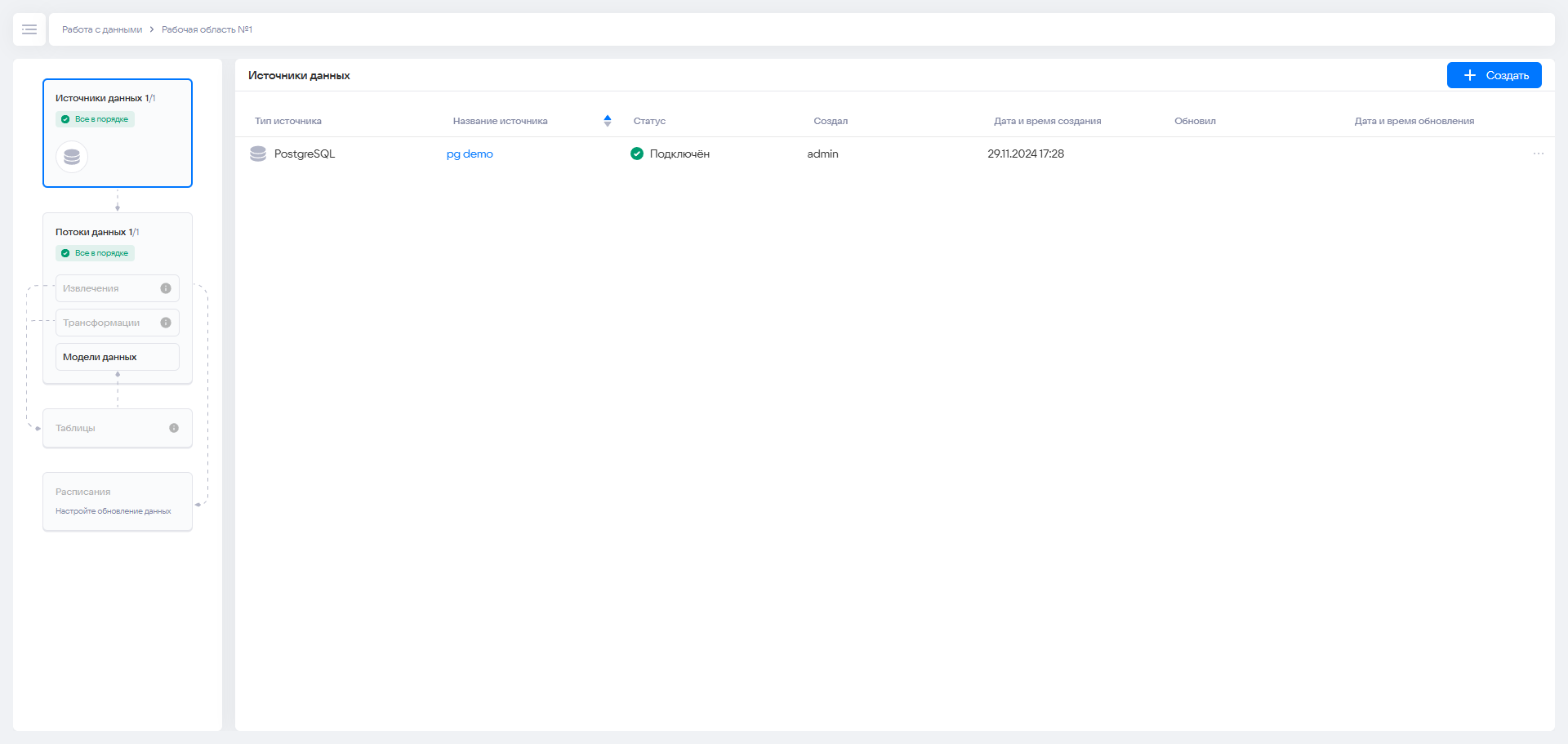
Нажмите на кнопку «Добавить источник» и в открывшемся окне заполните необходимые данные.
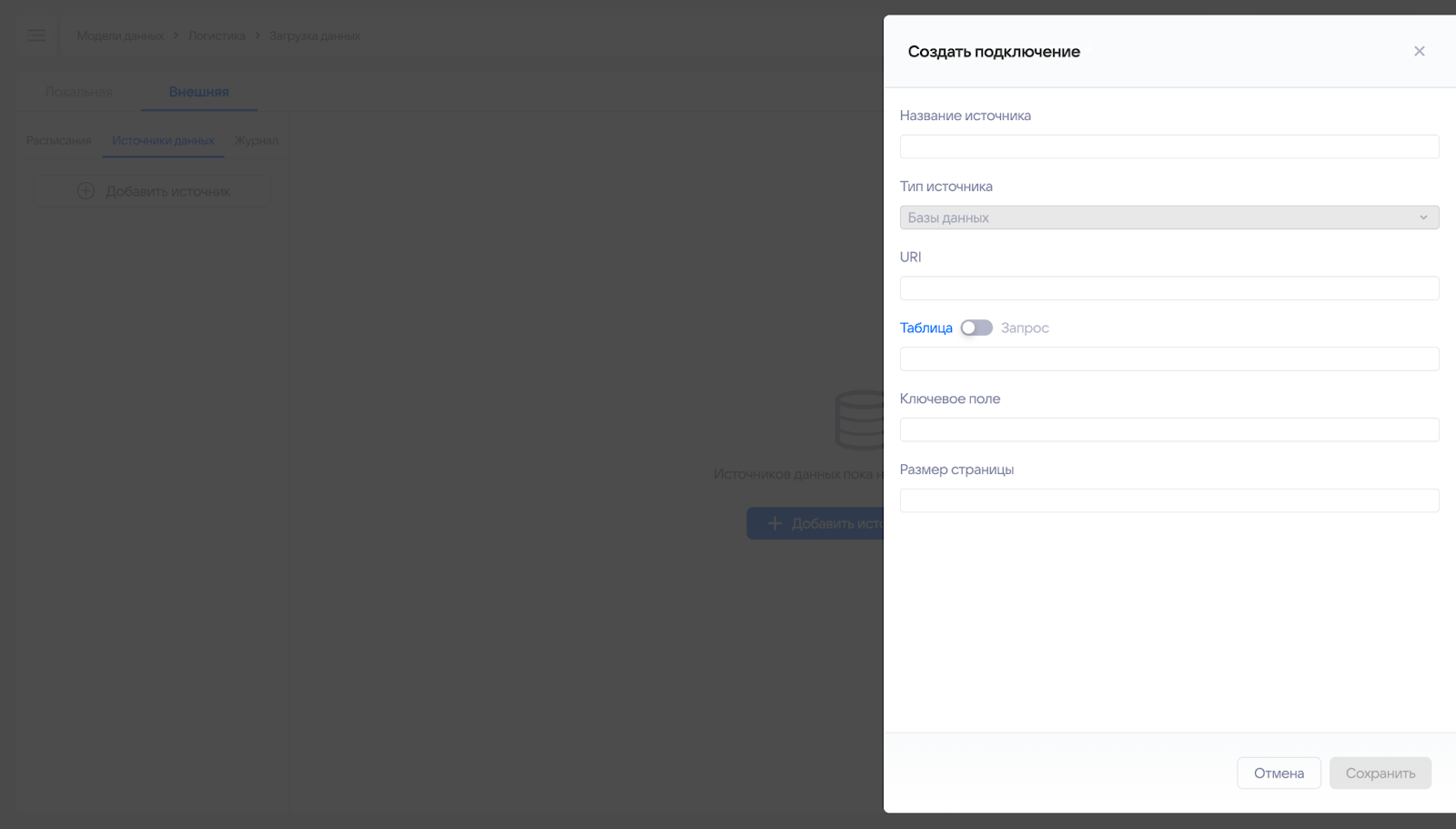
-
Название источника данных для отображения в интерфейсе.
-
Тип источника данных (пока доступны только Базы данных).
-
URI источника для подключения к БД. Описание структуры https://docs.sqlalchemy.org/en/14/core/engines.html#database-urls.
-
Указываем таблицу или запрос для базы данных, по которым будет производиться загрузка. Нельзя указать таблицу и запрос одновременно. Тут также указывается схема, если она есть.
- При указании таблицы, к БД будет выполнен запрос
select * from table. - При переведении переключателя в положение “Запрос” требуется указать SQL-запрос, по которому будет производиться загрузка.
- При указании таблицы, к БД будет выполнен запрос
-
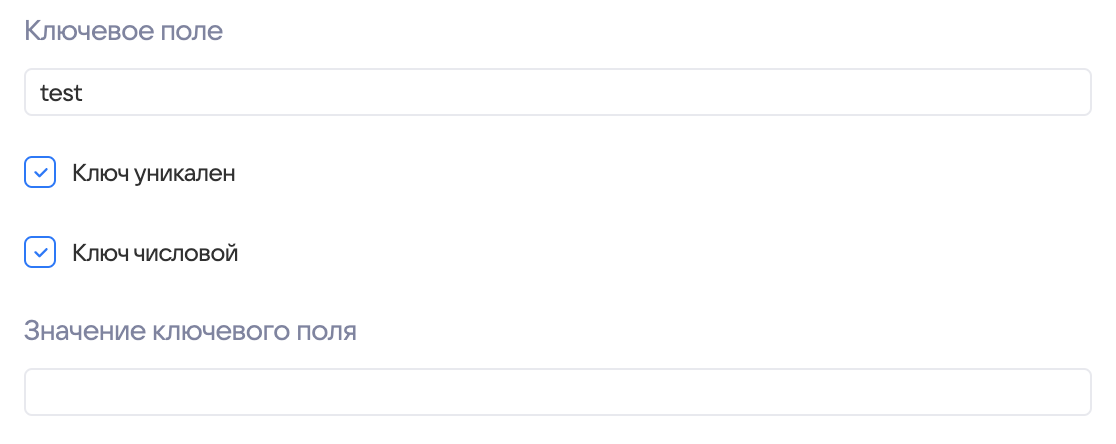
Ключевое поле — указывается название поля в БД, по которому будут загружаться данные. Его нужно указывать, если в таблице очень много строк (! без него будет полный запрос без limit) или если будет настраиваться инкрементальная загрузка. Если указать ключевое поле, то будут показаны дополнительные настройки.
- Ключ уникален — ключ может быть не уникальным, но тогда количество одинаковых значений по этому ключу должно быть меньше размера одной пачки.
Например, если происходит загрузка событий и у них нет своего уникального идентификатора. Для загрузки в ключевое поле был вписан идентификатор экземпляра процесса (process_id). Тогда количество событий по одному идентификатору экземпляра процесса не должно превышать 100000. (Если брать настройки по умолчанию в 100000 строк у поля «Размер страницы»). - Ключ числовой — указание на тип ключа «строка» или «число».
- Значение ключевого поля - Тут можно указать с какого значения начать грузить данные из базы. При загрузке инкремента, система автоматически сюда запишет последний ключ, который она загрузила, чтобы следующую загрузку начать с него.
- Ключ уникален — ключ может быть не уникальным, но тогда количество одинаковых значений по этому ключу должно быть меньше размера одной пачки.
-
Размер страницы — загрузка данных из БД происходит пачками, если указано Ключевое поле. В данном поле указывается ее размер. Данное значение будет подставлено в запрос к базе. По умолчанию, если ничего не указать, то она будет равна 100000 или тому, что указано в глобальном конфиге системы (редактирование доступно администратору кластера).
Для следующей конфигурации источника, к БД будет сформирован первый запрос:
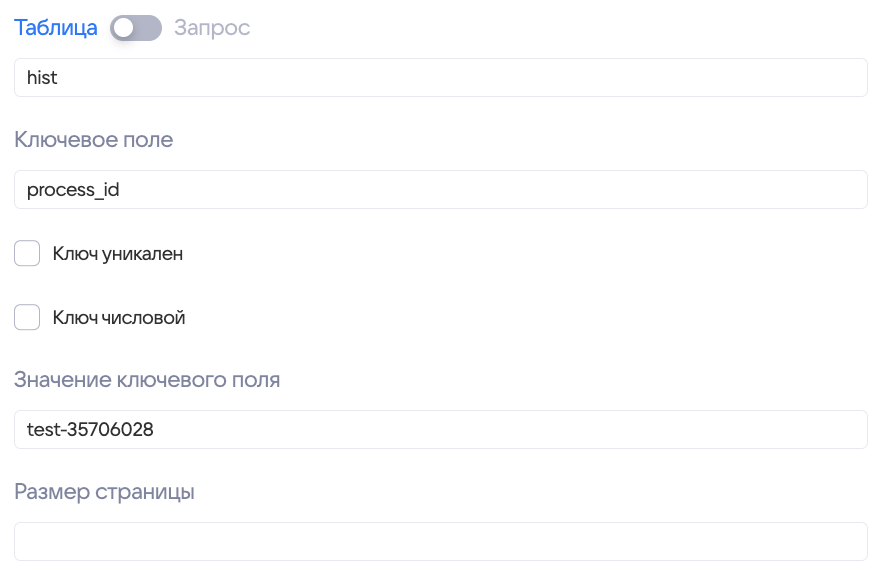
select *
from hist
where process_id > ''
order by process_id
limit 100000
Для последующих пачек будет сформирован запрос уже по последнему полученному идентификатору. И так пока все данные не будут загружены.
select *
from hist
where process_id > 'test-35706028'
order by process_id
limit 100000
Когда загрузка завершится, в источнике будет отображаться последний загруженный идентификатор. В следующий раз загрузка пойдет от него.

Важные уточнения работы с SQL запросом к источнику и ручным ограничение объема загрузки
Допустим для источника используется SQL-запрос. Если в нем указать лимит на загрузку строк, к примеру,
limit 1000, и задано ключевое поле, то система будет считать, что задано поле "Размер страницы"=1000. То есть 1000 указанная в запросе будет относиться к размеру страницы, а не к ограничению объема. То есть будут загружены все строки из таблицы пачками по 1000.При этом, если ключевое поле задано и используется запрос, то в этой комбинации система ожидает в тексте запроса параметр
$keyи меняет его на последнее загруженное значение ключа, чтобы для каждой очередной пачки знать, куда подставить значение ключа в запрос, отчего может возникнуть ошибка при загрузке. Также можно указатьlimit $limitвместо статического значения 1000. В этом случае значение размера страницы будет подтягиваться из настроек источника (поле «Размер страницы») или глобальных настроек системы (по умолчанию, если не задан «Размер страницы»).
$keyи$limitуказываются только для случая, когда задано ключевое поле. Пример запроса:select * from hist where process_id > $key order by process_id limit $limitНо если убрать ключевое поле — 1000 становится ограничением объема. Таким образом загружается не весь объем источника, т.к. для системы весь объем — это первые 1000 записей и она не знает про остальные.
Расписания
На вкладке Расписания происходит настройка загрузки данных в таблицы, созданных на Шаге 1, из источников, настроенных на Шаге 2 раздела Источники данных. Для того, чтобы это сделать, нажмите на кнопку Добавить расписание. В появившемся окне заполните необходимые данные:
- Название расписания — название задания для отображения в интерфейсе.
- Дата начала загрузки — укажите дату и время начала загрузки. В случае, если загрузка была указана в прошлом, — расписание начинается сразу после включения. Время запуска роли не играет.
- Периодичность запуска. Значение по умолчанию: “Разовый запуск задания”. При необходимости, снимите флажок и установите периодичность выполнения через выпадающие списки: ими будет сформировано cron правило.
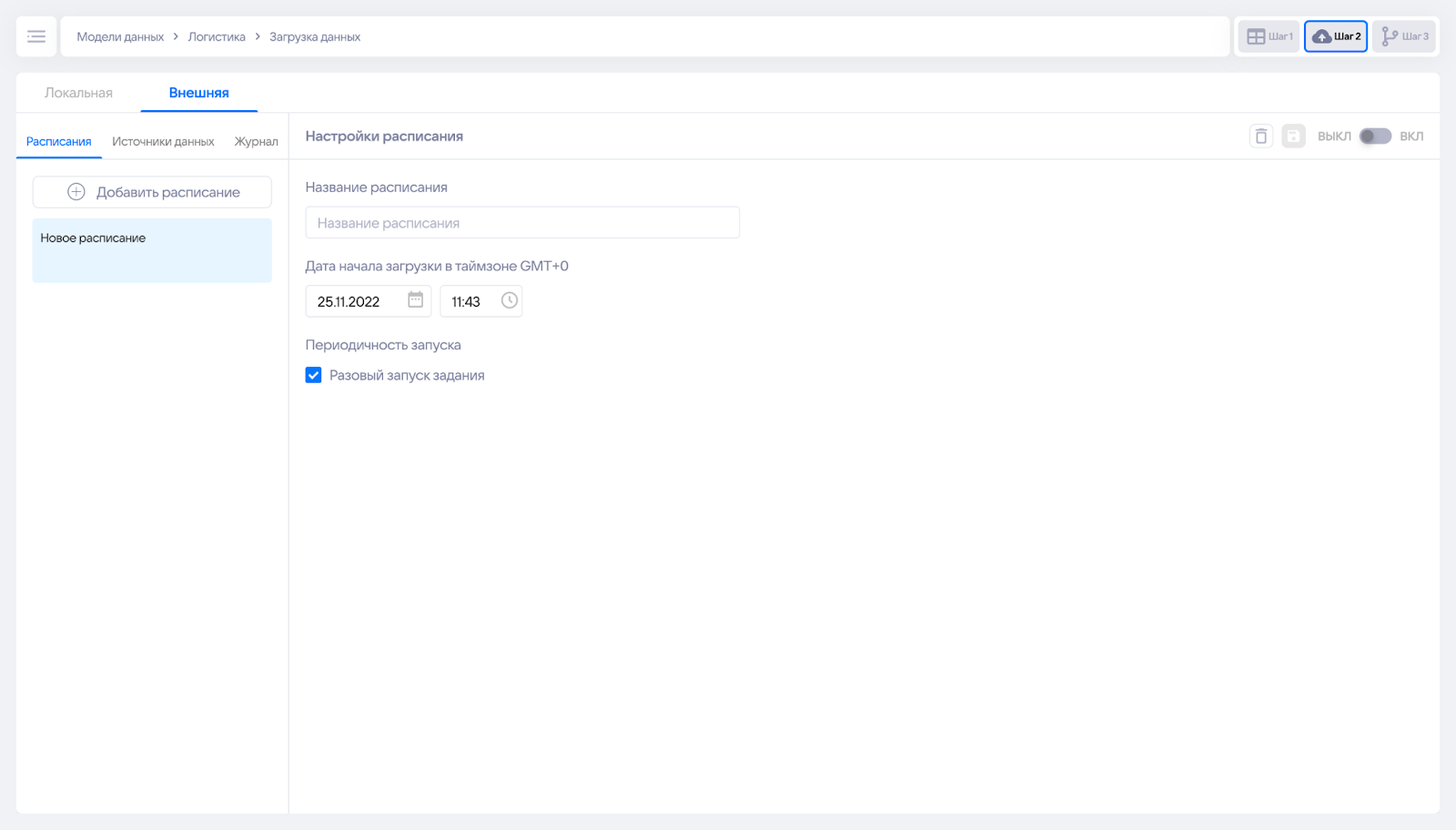
Далее необходимо сохранить расписание, чтобы продолжить с ним работу, нажав на кнопку сохранения в правом верхнем углу интерфейса.
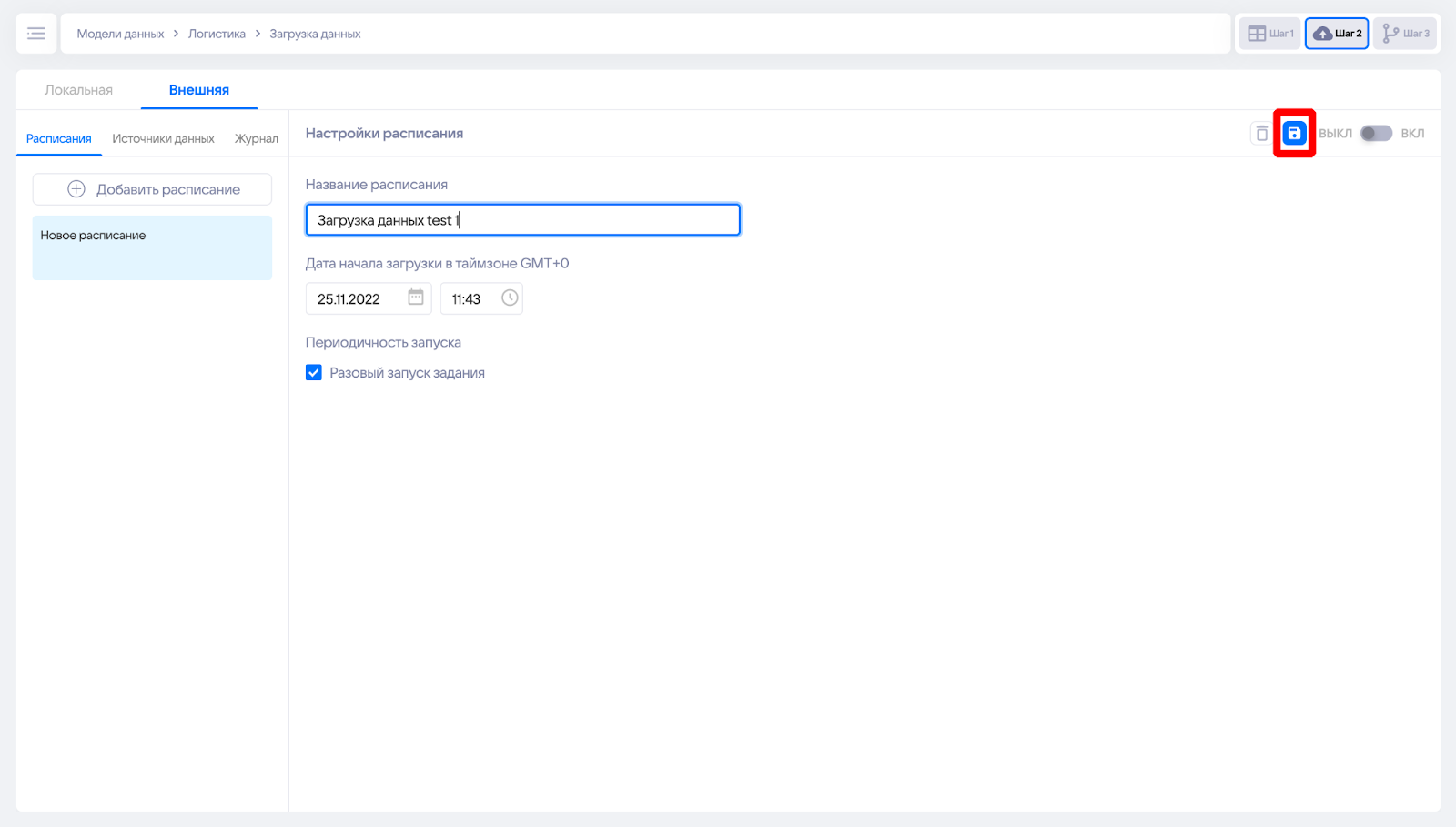
После сохранения появляется интерфейс добавления задач в расписание. С помощью них можно выставить последовательность действий с моделью.
Например, может быть реализован следующий сценарий:
- Задача 1. Полная очистка целевой модели или очистка по фильтру, например, дате.
- Задача 2. Загрузка атрибутов экземпляров процессов.
- Задача 3. Загрузка событий и их атрибутов.
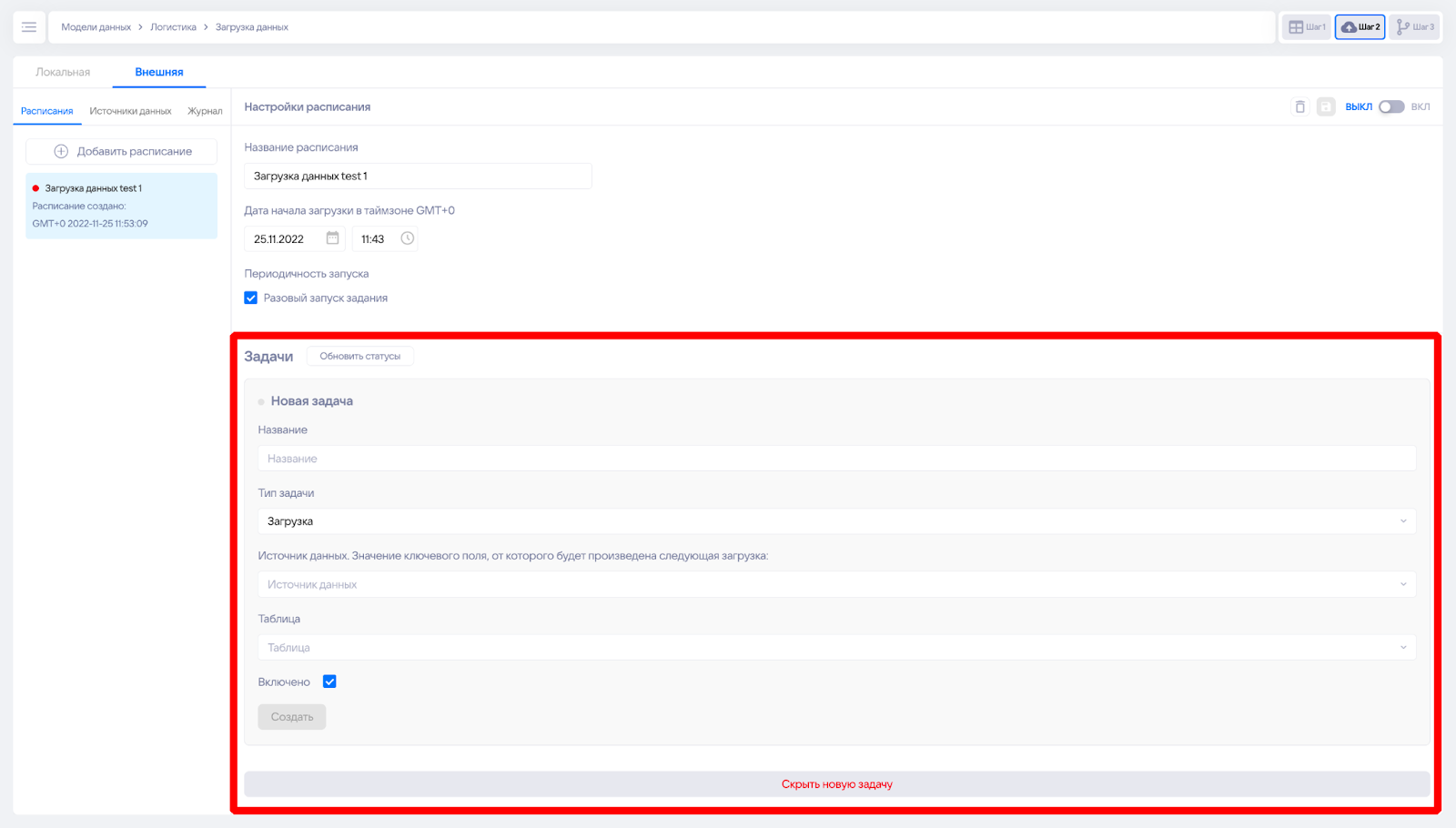
У задачи для заполнения доступны следующие поля:
- Название для отображения в интерфейсе.
- Тип задачи. В зависимости от него доступны разные поля для заполнения:
- Загрузка,
- Удаление.
Тип загрузка
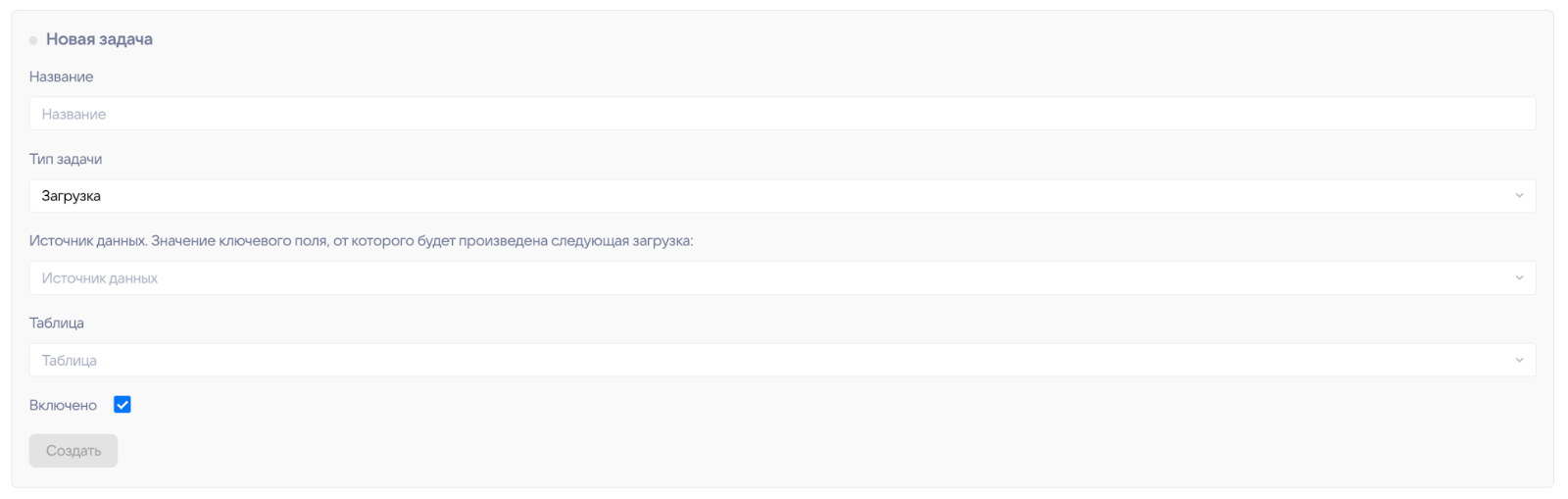
- Источник данных. Выберите из выпадающего списка ранее созданный источник.
- Таблица. Выберите из выпадающего списка ранее созданную таблицу, в которую будут загружаться данные.
Тип удаление

- Выберите правила, по которым будет производиться очистка данных.
¶ Шаг 3: Трансформация
На этом шаге созданные таблицы связываются между собой скриптом на языке Lua. Скрипт привязывается только к основной таблице — таблице событий. Данный скрипт срабатывает на каждой строке и записывает данные в целевые таблицы process и event.
Если данных много, то рекомендуется сразу добавить скрипт трансформации. Он нужен для того, чтобы данные в сырой таблице событий не копились, а удалялись сразу после обработки и трансформации загруженной пачки. Размер пачки настраивается в источнике в поле «Размер страницы». При этом данные в справочниках (не основные таблицы) удаляться не будут.
Пример скрипта трансформации:
function(row, modelUid)
local process = {
extId = row.process_id
}
local p_attrs = getSpace('attr2', modelUid):get(row.process_id)
if p_attrs ~= nil then
p_attrs = tomap(p_attrs)
p_attrs.close_date_time = p_attrs.close_date_time
process.attrs = p_attrs
end
local event = {
name = row.name,
started = row.started,
ended = row.started,
sorting = row.sorting,
attrs = tomap(row)
}
event.attrs.name = nil
event.attrs.process_id = nil
event.attrs.started = nil
event.attrs.date_out_tz = event.attrs.date_out_tz
process.attrs.process_id = nil
return process, event
end
¶ Календарь процесса
Календарь позволяет добавить рабочее расписание, праздничные дни и дополнительные рабочие дни, чтобы пересчитать статистику длительностей.
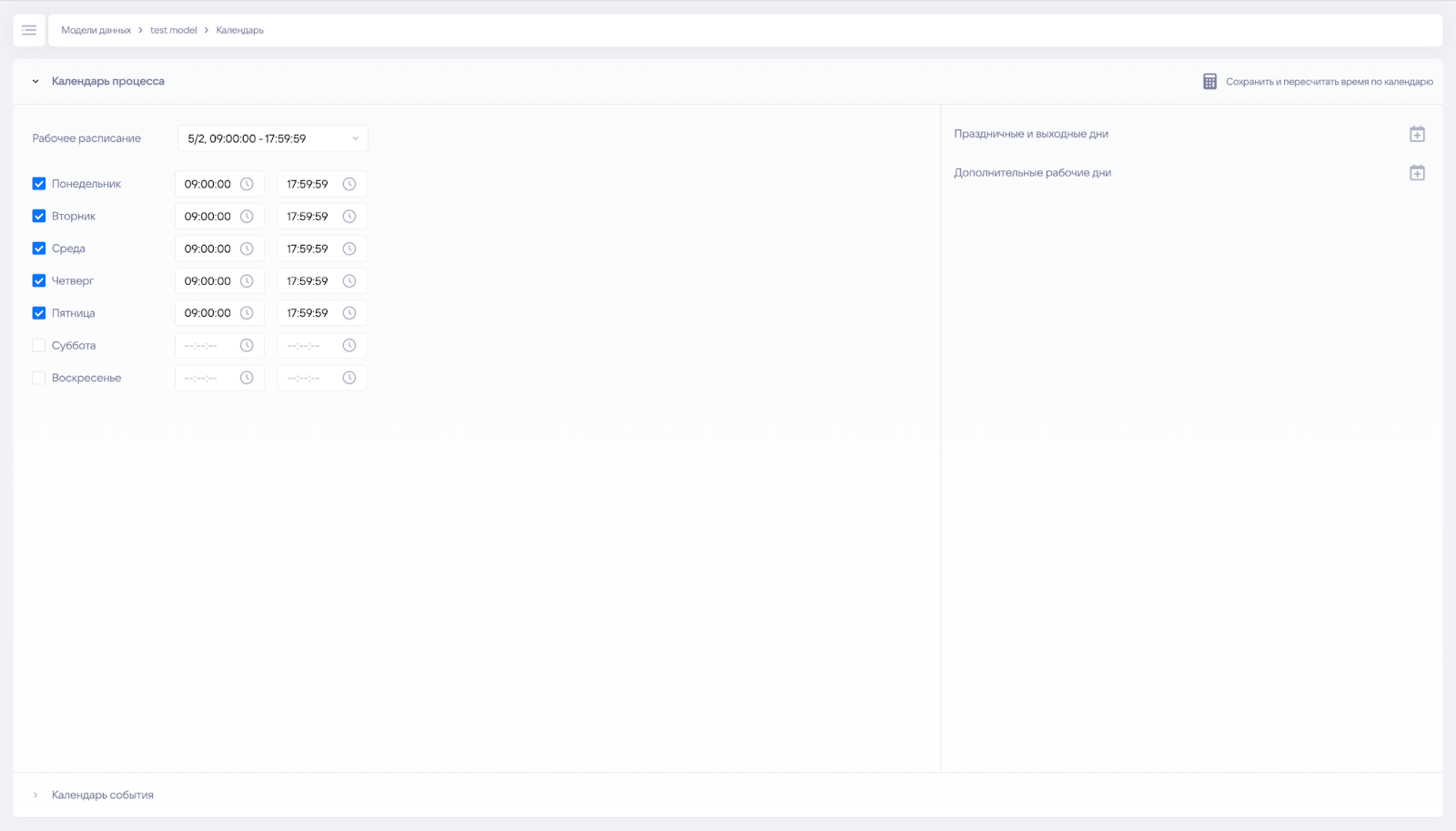
Для каждой модели можно добавить свой календарь, но он будет одним на всю модель.
¶ Использование пересчитанных данных по календарю
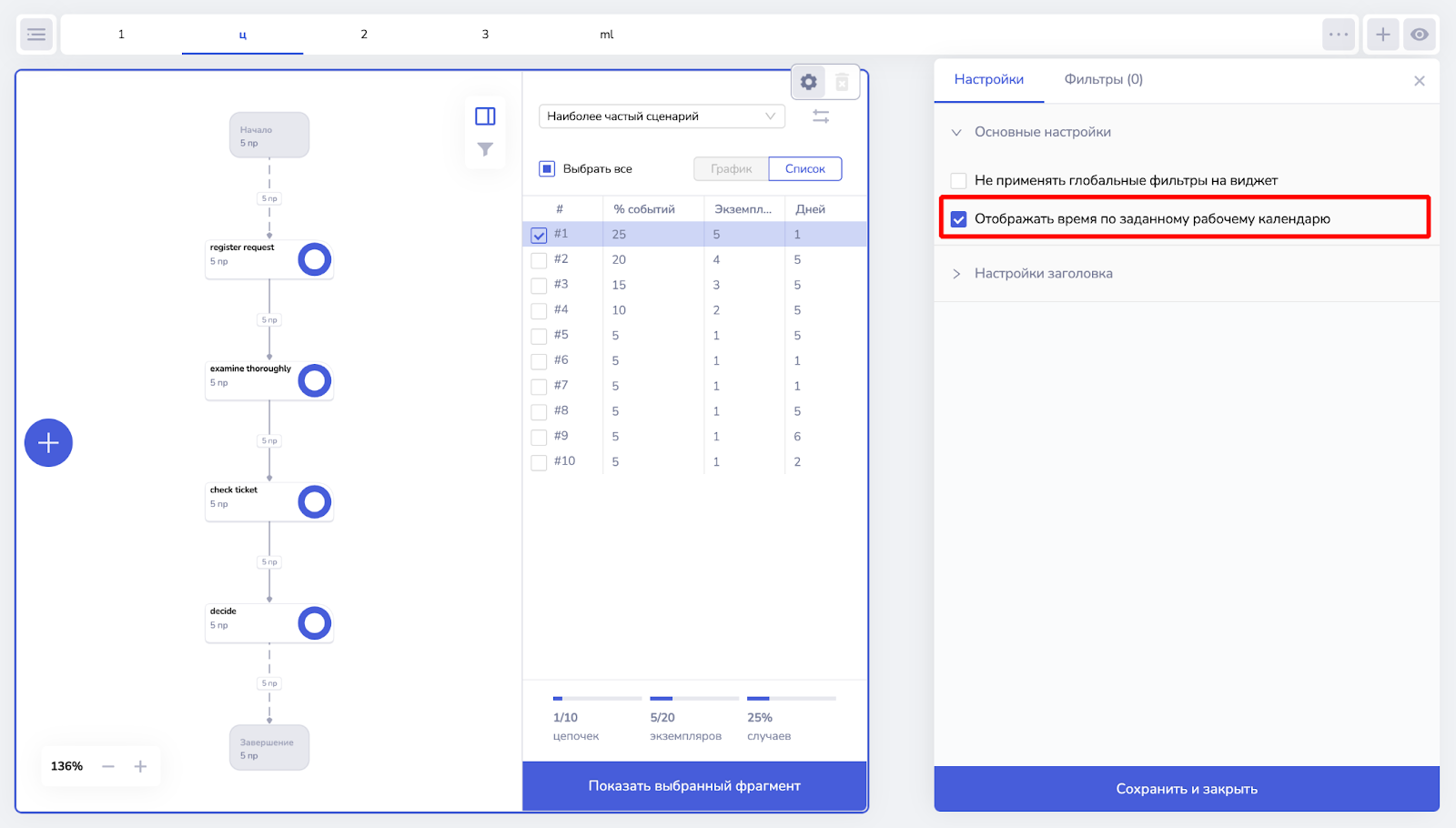
Виджеты Variant Explorer, Case Explorer, Lead Time (Преднастроенные виджеты)
Чтобы увидеть пересчитанные значения по календарю в преднастроенных виджетах Variant Explorer, Case Explorer и Lead Time необходимо открыть настройки виджета в режиме редактирования и выбрать чекбокс «Отображать время по заданному рабочему календарю».
Все остальные виджеты (Универсальные виджеты)
Чтобы увидеть пересчитанные значения по календарю в универсальных виджетах, например, таблицах или гистограммах, необходимо при написании SQL-запроса использовать колонки:
- durationSch — Длительность в секундах, рассчитанная по календарю.
- intervalSch — Интервал в секундах до предыдущего шага, рассчитанный по календарю.
Например, можно использовать следующий запрос, для сравнения показателей длительностей фактических и по календарю на каждом шаге:
select
name,
sum(durationFact) as "Длительность фактическая",
sum(durationSch) as "Длительность по календарю",
sum(intervalFact) as "Интервал фактический",
sum(intervalSch) as "Интервал по календарю"
from
event
group by
name
order by
name
Также для расчета интервалов между двумя шагами используется функция getdurationSch — подробное описание и примеры использования приведены в документе с описанием дополнительных SQL-функций.
Если нужно использовать в одной модели разные календари и поля durationSch/intervalSch не подходят, то можно использовать функцию workTime. Подробное описание и примеры использования приведены в документе с описанием дополнительных SQL-функций.
¶ Типы данных
Страница с типами данных позволяет работать с загружаемыми колонками в модель.
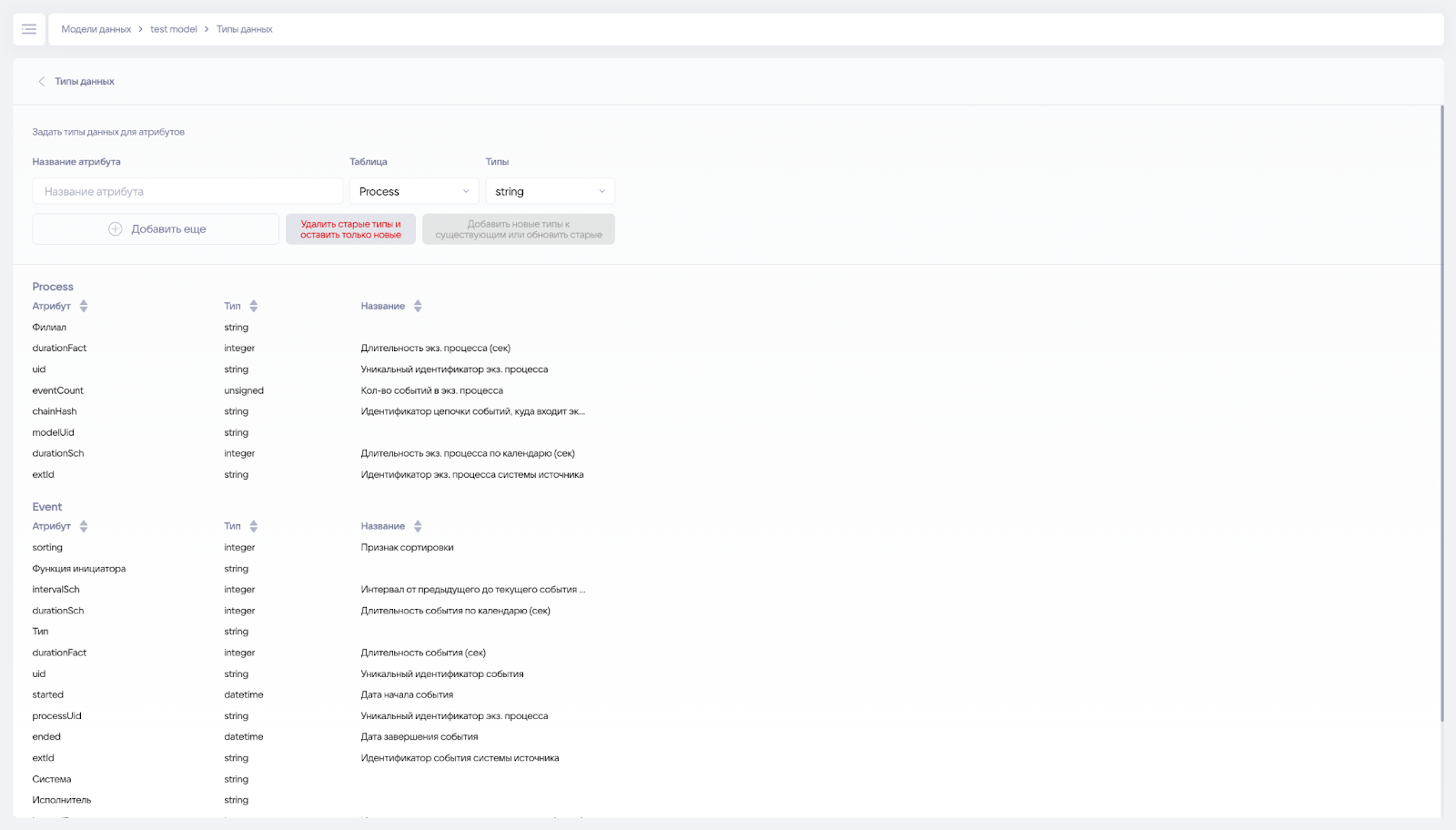
На ней можно выполнять следующие действия:
- Переопределять типы данных:
- Числовые типы (число, дата-время, boolean) можно преобразовывать друг в друга.
- Если преобразовать строковый в числовой и наоборот, то значения будут null.
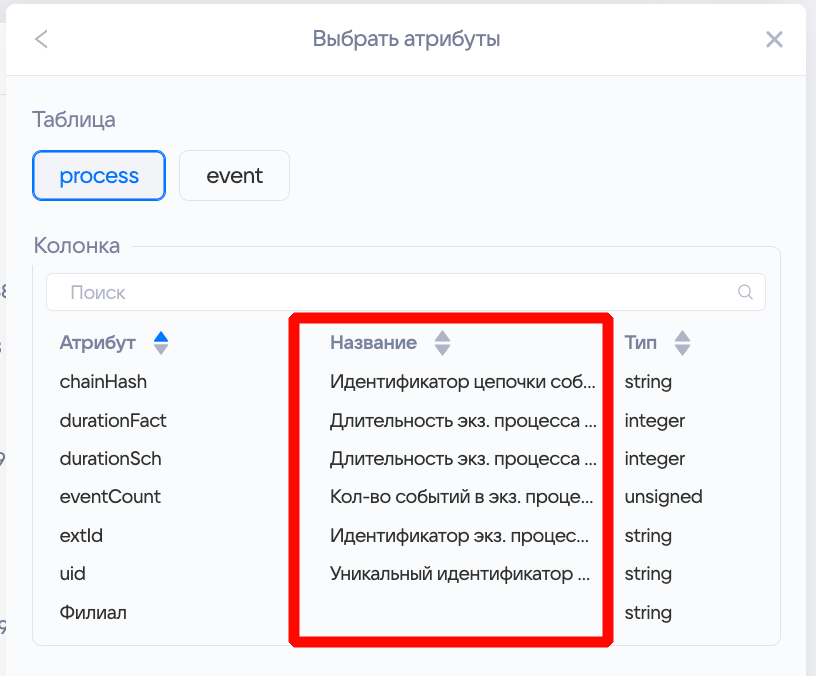
- Задавать названия для колонок. Далее с этими названиями можно работать пользователям в фильтре «Выбрать атрибуты».
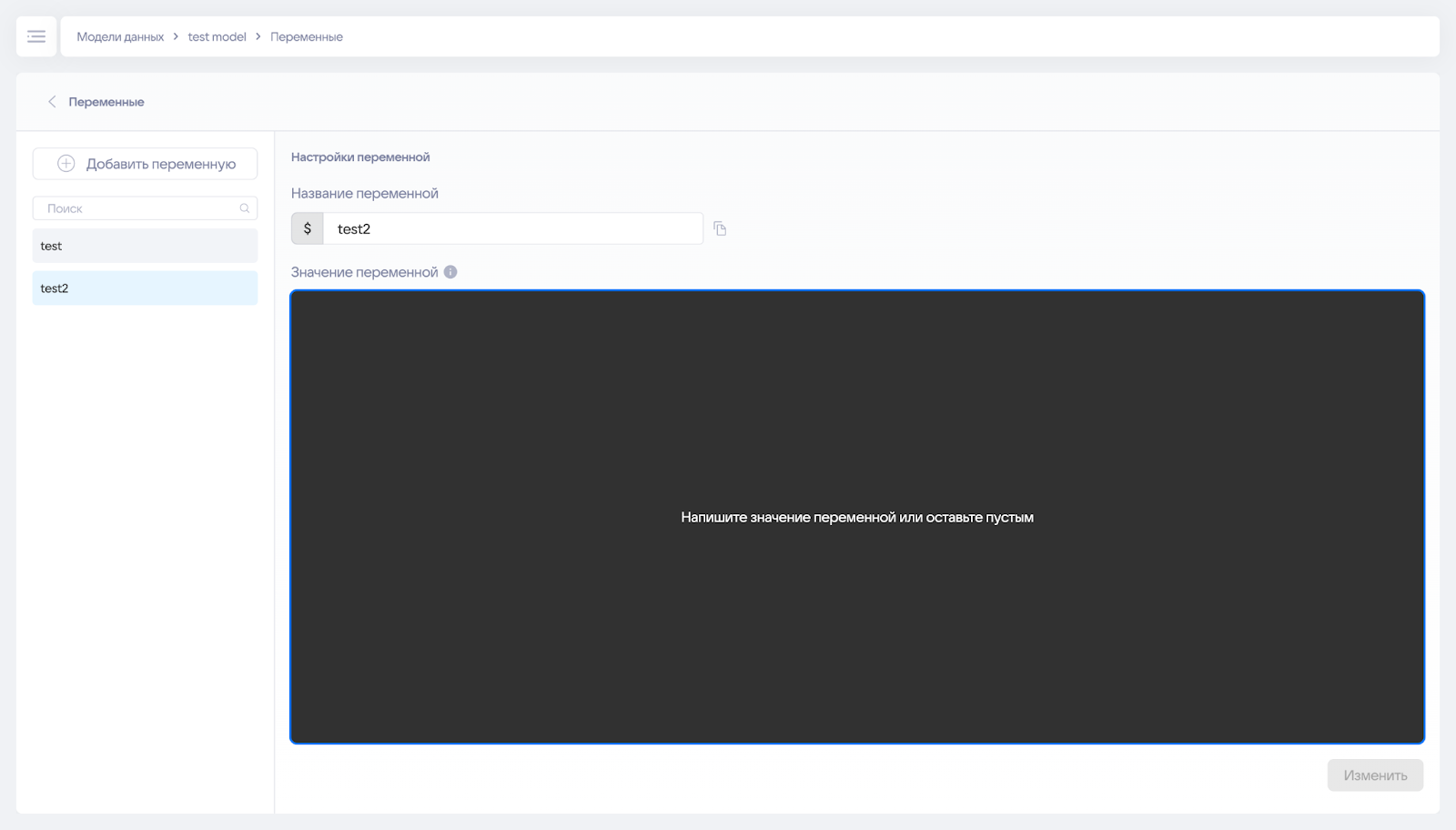
¶ Переменные
Страница позволяет задавать переменные.
Переменные бывают:
- статичные,
- динамические.
Сферы применения:
- Статичные переменные — Содержат в себе часть SQL-запроса или целый запрос. Можно:
- Вставлять из переменной часть SQL-запроса или целый запрос.
- Вставлять в заголовок виджета переменную, которая содержит в себе запрос. Он будет выполняться каждый раз при отображении данного виджета.
- Динамические переменные — По умолчанию создаются пустыми. Далее им можно присваивать разные значения с помощью выпадающих список в отчете.